I was very fortunate in 2011 to be awarded a Leading Edge Forum Grant to perform distinguished research on In-Memory Data Grid technologies (IMDG). At the time, the term Big Data had not been coined, or at least I had never heard of it. The 3 months of intensive study and research for the CSC Leading Edge Forum, now known as DXC Technology, lead to a path of self-discovery and a realisation of what was really happening in the data space. Here is a link to the brochure showcasing my work:
www.slideshare.net/CSC/csc-grants-via-leading-edge-forum

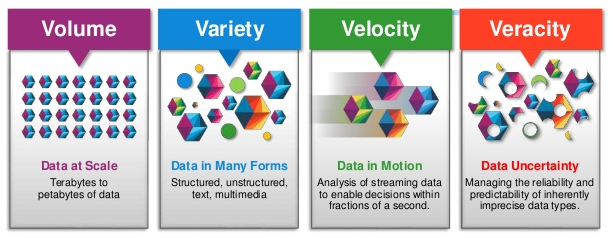
Big Data is now defined as the problem space, relating to the cleaning and analysis of huge data sets, resulting in a series of recommendations, a roadmap and/or defined business outcomes. It’s further described by using the 4 V’s:
- Volume – When I say huge data sets, I mean millions of records or entries. Think of Facebook logins.
- Velocity – Data hits us thousands of times per second across multiple channels. Think of Social Media feeds across multiple platforms and real-time data in hospitals.
- Variety – Data is mostly unstructured or semi-structured. Think of payments, pictures, videos, blogs, tweets, MRI scans and sensor data.
- Veracity – Refers to the quality and relevance of data for the task in hand. Data scientists often refer to high veracity as finding the signal in the noise.
Based on my research, and because of my classical / jazz composition background, I see Big Data slightly differently. You see when I studied musical composition at the University of Wales and the London College of Music, I learnt that the most talented composers and performers had been using the same system for around 500+ years.
Sounds remarkable, that a single system would pervade for so long, but it’s true. We call it tonality, or in laymans terms we use keys and scales in music. When we learn to play a musical instrument we learn all the different scales and all the different keys. Examples include C Major, D minor, B flat major or C# minor. This is why there is much emphasis on practicing scales and chords. This system is called the tonal system and is still strongly used in pop music culture, especially in the pop music charts.
Now…at the turn of the century, between 1900 and 1925 a group of composers emerged, that are now called the Second Viennese School. And what they did was remarkable. They pretty much started to reject the use of the tonal system, that had served mankind well for 500+ years and created a new form of music called serialism. Simply put, that is music that does not have a tonal centre, a key or is not strictly part of a scale. We describe this as atonalism. To the untrained ear, it would appear that the notes seems to be random and dissonant. This is what atonal music, using serialism composition can look like.

You’ll see that every note on the top stave is never repeated and every note on the bottom stave is also never repeated. This ensures that no note takes precedence and stops us perceiving any form of tonal centre, or tonality. Below is a short video explaining serialism, if you’re interested in learning more.
www.youtube.com/watch?v=c6fw_JEKT6Q
This new school of serialism, led by Schonberg, Webern and Berg, was mirrored in the art and fashion worlds, through the abstract art movement, with Jackson Pollock being the most famous. Below is an example of Pollock’s work:

So what the hell does this have to do with Big Data, I hear you cry?
Well Big Data is a great analog of this short history lesson in modern musical composition theory. We’ve been using relational datastores for 30 years, and apart from the emergence of a few exceptions, the most popular datastores have been SQL based, conforming to relational database theory. These datastores are commonly known as relational database management systems or RDBMS. Think of relational database theory as musical tonal theory. It’s worked for a long time, so why change it? Examples of RDBMS include Microsoft SQL, Oracle and SAP. With a relational datastore, we store data in tables and these tables all relate to each other in a schema. Below is a simple example:
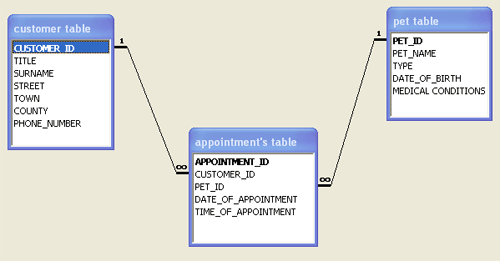
There are other rules that need to be implemented in order for a relational datastore and these include following the ACID principles, and rationalising the structure using normal forms. Here is a good article outlining relational database theory:
en.wikipedia.org/wiki/Relational_database
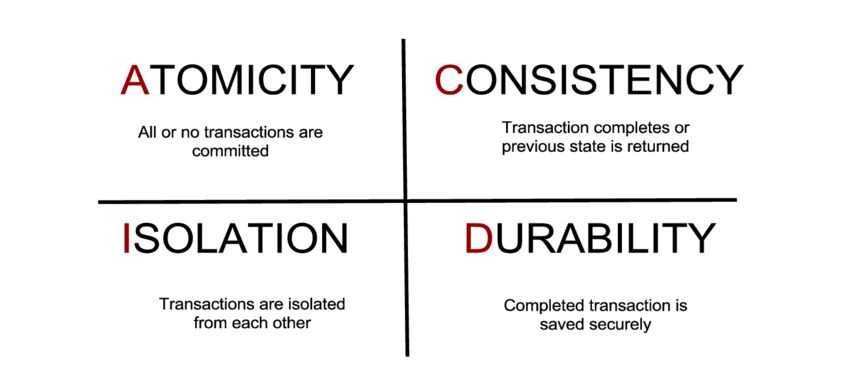
Then companies decided to rethink the storage of data, to help solve new, complex problems. The challenge with relational datastores is that they are great at storing customer information and financial information, but are not very good at processing and storing millions of records, that are unstructured, with 1000s of additional unstructured data items being thrown into the mix per second, with varying levels of data quality. Basically relational datastores are not built to cope with Big Data. They tend to be much slower, reliant on ACID principles, and are not optimised for handling unstructued or semi-structured data. The diagram below outlines ACID principles in an RDBMS architecture:
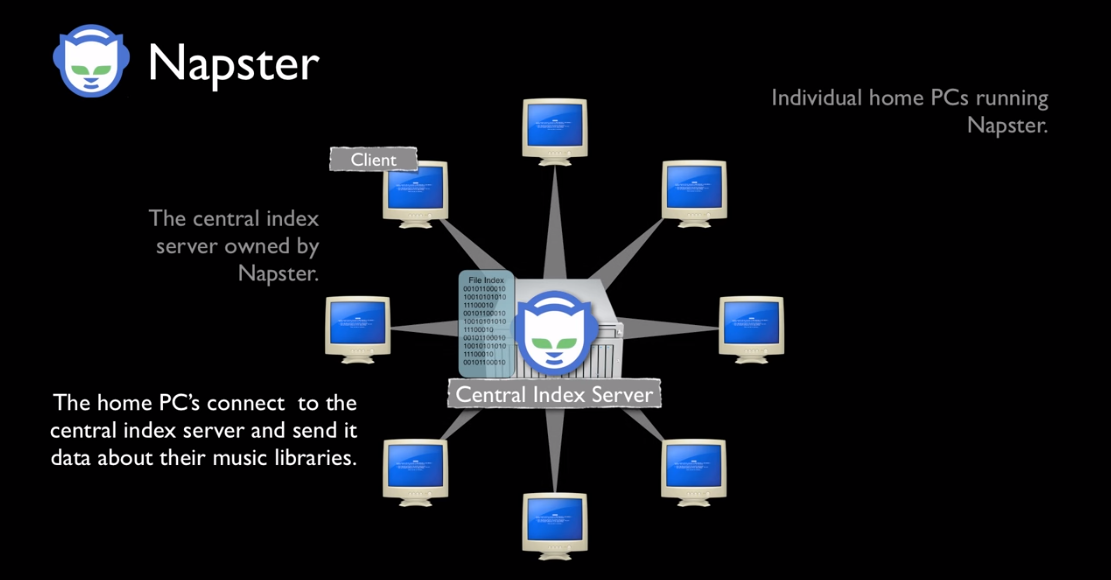
The first well known company to use non-relational datastores en-mass was Napster. They created a peer-to-peer music sharing network in the early 2000’s and used distributed hash tables to link up the data via central servers. A distributed hash table is essentialy a key value store, which links a key (name of the song and artist), with a value (a link to the mp3 file). This means it’s super fast and able to reference unstructured data very efficiently. This provided a very successful, timely and ground-breaking music streaming service, similar to Spotify today. In those days Napster was later shown to be an illegal service, which has since reached agreements with record companies and artists. Click on the diagram below to view a short video outlining how Peer to Peer networks operate:
In parallel we see Google invent Apache Hadoop technologies to deal with vast quantities of indexing material for search engines and the Big Data ecosystem grows expotentially from there. We now have NOSQL datastores, In-Memory Data Grids and the list goes on. Here is an article that best describes the key differences between the most common types of technology: NOSQL, RDBMS and Hadoop:
www.datasciencecentral.com/profiles/blogs/hadoop-vs-nosql-vs-sql-vs-newsql-by-example
Be aware that there is huge complexity and variation between different types of Big Data products. The diagram illustrates this point, by outlining the current Hadoop suite of software tools, that can be utilised in a Big Data initiative.
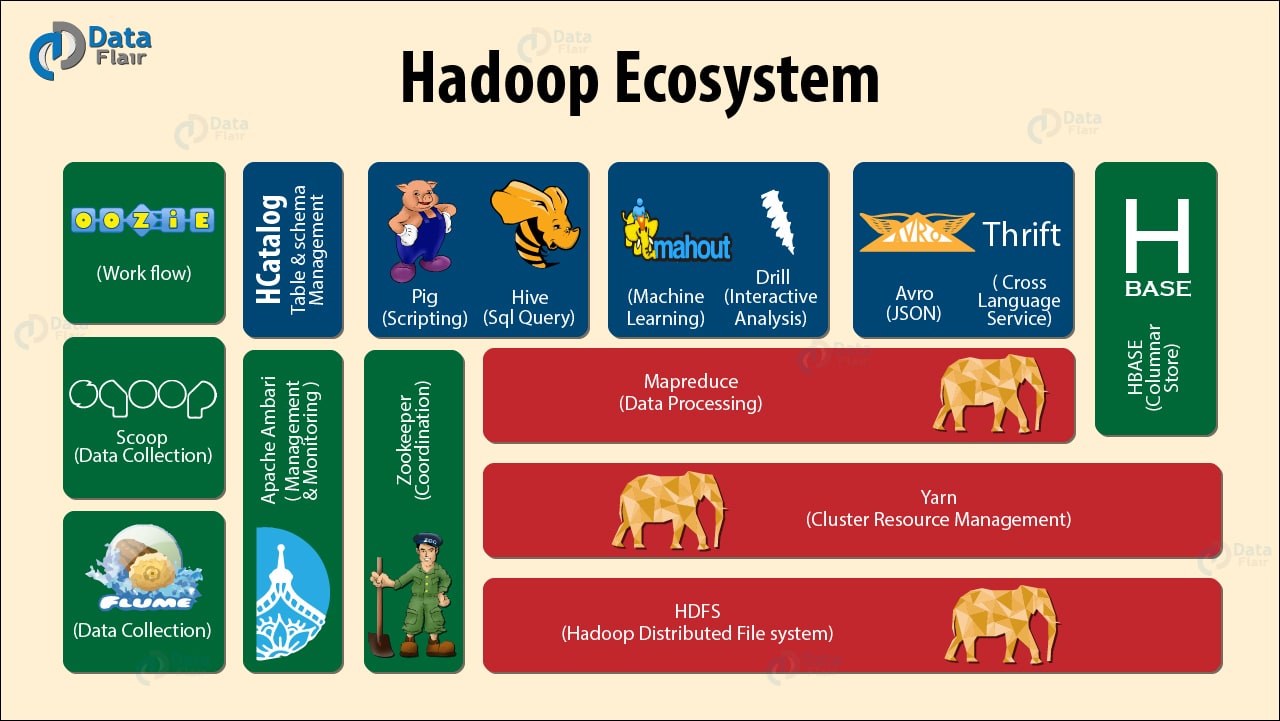
Unfortunately we haven’t had enough time to cover Artificial Intelligence, Machine Learning and Deep Learning, which I’ll save for another blog post. But these techniques, methods, approaches are all part of the Big Data movement.
If you’re interested in learning more about Big Data technologies, check out our new Enterprise Big Data Professional course:
www.alctraining.com.au/courses/cloud-computing/
